Serving Tenant-Specific Content from a Single Global Deployment
Most multi-tenant SaaS systems start life in a silo model. Each enterprise customer gets their own deployment, their own subdomain, usually their own backend, and a routing story so obvious nobody even calls it routing.
Most multi-tenant SaaS systems start life in a silo model. Each enterprise customer gets their own deployment, their own subdomain, usually their own backend, and a routing story so obvious nobody even calls it routing.
app.clienta.product.com talks to api.clienta.product.com. app.clientb.product.com talks to its own stack. The tenant boundary is baked into the URL, so the application barely has to think about it.
That stops being true the moment you build something shared.
A support portal. A unified docs site. A status page. A global admin surface. Now you have one frontend deployment serving many tenants, but the content behind it is still tenant-specific. The infrastructure is no longer resolving tenant context for you. Your application has to do it deliberately, and if you do it badly, users see the wrong branding, the wrong documentation, or, in the worst case, the wrong data.
This is the part people underestimate. Consolidating deployments removes infrastructure sprawl, but it does not remove tenant-routing complexity. It just moves that complexity into the application layer.
The clean way to handle it is to make tenant resolution explicit, server-side, and configuration-driven.
Start with one idea: every incoming request needs a tenant context before anything else happens. That context tells the application which tenant the request belongs to, which backend owns that tenant's content, what authentication policy applies, and which presentation rules the frontend should use.
type TenantContext = {
tenantId: string;
tenantSlug: string;
backendBaseUrl: string;
docsEndpoint: string;
authMode: 'public' | 'required';
};
Once you have that object, the rest of the system gets simpler. Your UI stops guessing. Your API routes stop branching on random conditions. Your logging has a stable tenant key. Most importantly, adding a new tenant becomes a config change instead of a code change.
Hostname resolution is usually the strongest first choice. If you can give every tenant a dedicated support hostname such as support-clienta.product.com, do that. It preserves the same mental model your silo architecture already used, and it gives you a reliable lookup key before the user has even logged in.
In larger systems, this registry may live in a configuration service or edge KV store, but the architectural principle stays the same.
const tenantRegistry: Record<string, TenantContext> = {
'support-clienta.product.com': {
tenantId: 't_123',
tenantSlug: 'clienta',
backendBaseUrl: 'https://api.clienta.product.com',
docsEndpoint: '/docs/active',
authMode: 'required',
},
'support.product.com': {
tenantId: 'staging',
tenantSlug: 'staging',
backendBaseUrl: 'https://staging-api.product.com',
docsEndpoint: '/docs/active',
authMode: 'public',
},
};
export function resolveContextFromHost(hostname: string): TenantContext | null {
return tenantRegistry[hostname.toLowerCase()] ?? null;
}
That registry can live in code, a database table, or a configuration service. The storage choice matters less than the discipline. Keep it authoritative. Keep it versioned. Treat it as an allowlist, not as a suggestion. Never trust a tenant identifier sent from the browser when the hostname already gives you a stronger signal.
Path-based routing like /clienta/docs is still viable when hostnames are fixed, but it is a weaker boundary. It is easier to mistype, easier to cache incorrectly, and harder to brand cleanly. If you have to use it, validate the path segment against the authenticated user's tenant membership before you fetch anything sensitive. Do not let the path become a free-form tenant selector.
Authentication becomes the second resolver, not the first. For public content, the hostname is enough. For protected content, the session tells you whether the current user is actually allowed to see that tenant's data.
In practice, the flow is straightforward:
- Resolve the tenant from the hostname.
- Read the user session, if the route is protected.
- Verify that the session's tenant claims match the resolved tenant.
- Call the correct backend.
- Normalize the response before it reaches the UI.
That third step matters more than it looks. In a shared deployment, authentication and tenant resolution are related but not identical. A user can be authenticated and still belong to the wrong tenant for the current request. Treat tenant membership as an authorization check, not as a side effect of login.
There are two common patterns for backend calls once the session is established. The first is token forwarding: your support site passes the user's access token to the tenant backend, and the backend performs authorization itself. This is the cleaner security boundary when your downstream services already understand user tokens and scopes. Audit trails stay accurate, and the support layer stays thin.
The second is server-side delegation. Your support site validates the user session, resolves the tenant, and calls the backend with a service credential owned by the deployment. This is simpler operationally when cross-service token propagation is messy, but it means your shared frontend is now responsible for enforcing tenant authorization correctly. That is workable. It is just less forgiving of mistakes.
Either way, keep the browser out of backend selection.
The frontend should talk to a tenant-aware BFF layer, not directly to tenant APIs.
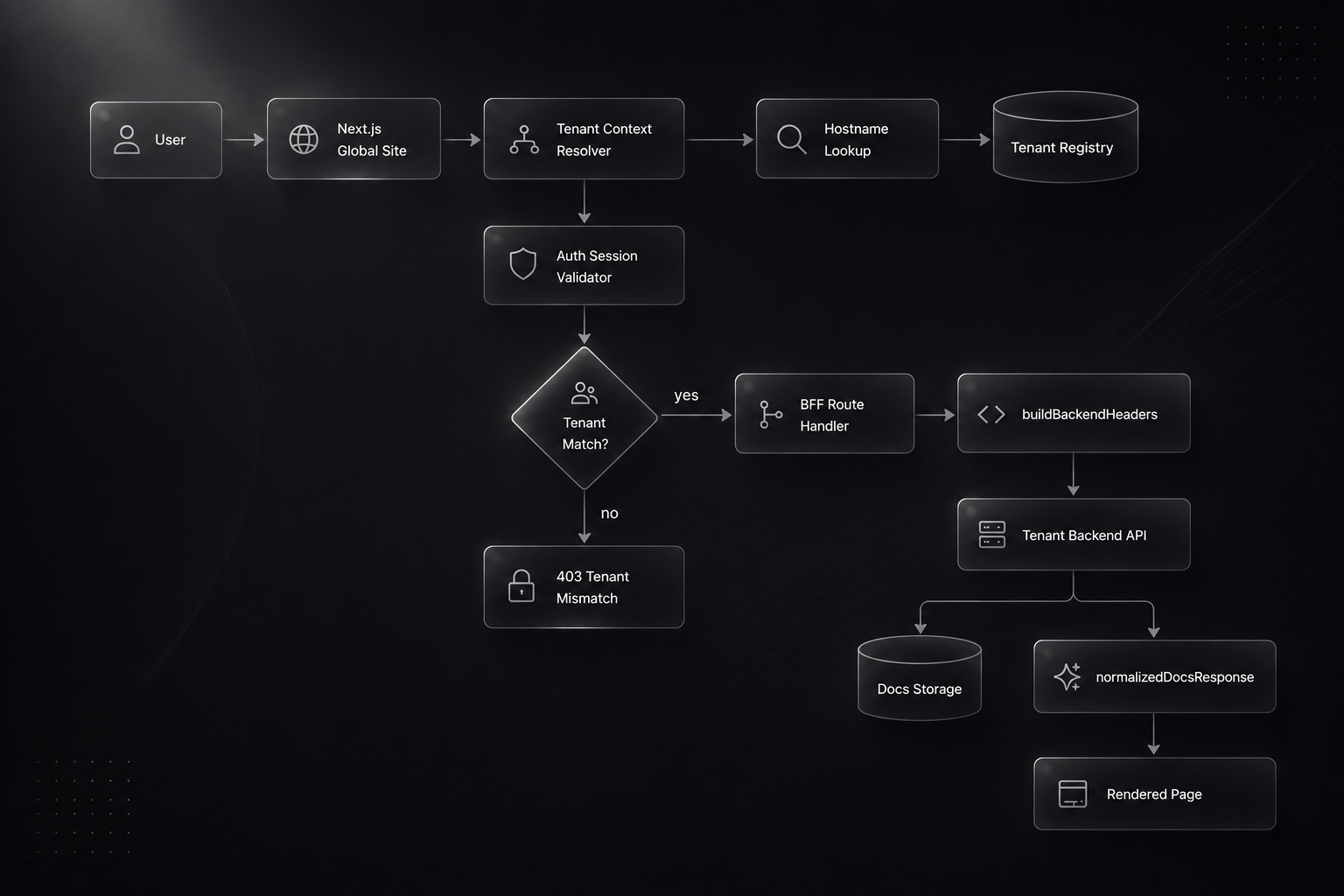
In a Next.js application, route handlers are a natural fit. They read the incoming host header, resolve the tenant context, inspect the session, call the correct backend, and return a stable JSON shape to the client.
import { headers } from 'next/headers';
import { NextResponse } from 'next/server';
export async function GET() {
const hostname = (await headers()).get('host') ?? '';
const context = resolveContextFromHost(hostname);
if (!context) {
return NextResponse.json({ error: 'Unknown tenant host' }, { status: 404 });
}
const session = await getSession();
if (context.authMode === 'required' && !session) {
return NextResponse.json({ error: 'Authentication required' }, { status: 401 });
}
// A valid session is not enough. The session must belong to this tenant.
if (session && session.tenantId !== context.tenantId) {
return NextResponse.json({ error: 'Tenant mismatch' }, { status: 403 });
}
const response = await fetch(`${context.backendBaseUrl}${context.docsEndpoint}`, {
// buildBackendHeaders attaches auth credentials based on your chosen pattern:
// token forwarding (passes the user token) or delegation (uses a service credential).
headers: await buildBackendHeaders(session, context),
cache: 'no-store',
});
if (!response.ok) {
return NextResponse.json({ error: 'Upstream request failed' }, { status: response.status });
}
const data = await response.json();
return NextResponse.json({
tenant: context.tenantSlug,
// normalizeDocsResponse maps the upstream shape to a stable contract your UI depends on.
// If the tenant backend changes its response format, this is the only place you update.
articles: normalizeDocsResponse(data),
});
}
This pattern buys you a lot. Backend URLs never leak into the browser. Cross-tenant logic lives in one place. Response normalization happens once instead of scattered across components. If a tenant backend changes its response shape, your UI does not need to care.
A few implementation details are worth getting right early.
Cache keys must include tenant identity. If two tenants hit the same route and your cache key is only the pathname, you have built a data leak with better latency.
Observability must include tenant context. Add the resolved tenant ID, hostname, and upstream backend to your logs and traces. Shared deployments are easy to operate right up until an incident, and then every missing field becomes a wasted hour of grepping.
Fallback behavior must be explicit. Decide what happens for unknown hosts, disabled tenants, and partially configured environments before you ship, not after. Returning staging content for an unrecognized enterprise hostname feels convenient during development. In production, it is the kind of shortcut that becomes a support ticket.
On resolution order: keep it strict. Hostname beats path. Authenticated tenant membership beats an unauthenticated route hint. A server-side registry entry beats any client-provided tenant value. That hierarchy is what keeps the system predictable when things get weird.
The bigger point is not that a global deployment is difficult. It usually is not. The real shift is that tenant awareness becomes an application concern the moment you stop isolating deployments per customer. Make that concern explicit, centralize it in a registry, and enforce it through a server-side BFF, and the design stays clean. Scatter it across components, query parameters, and frontend conditionals, and it turns into a quiet mess that is unpleasant to debug.
Single deployment, many tenants, one routing brain. That is the model. Everything else is implementation detail.`